
README.md 61 KB

RTMPose: Real-Time Multi-Person Pose Estimation toolkit based on MMPose
RTMPose: Real-Time Multi-Person Pose Estimation based on MMPose
Abstract
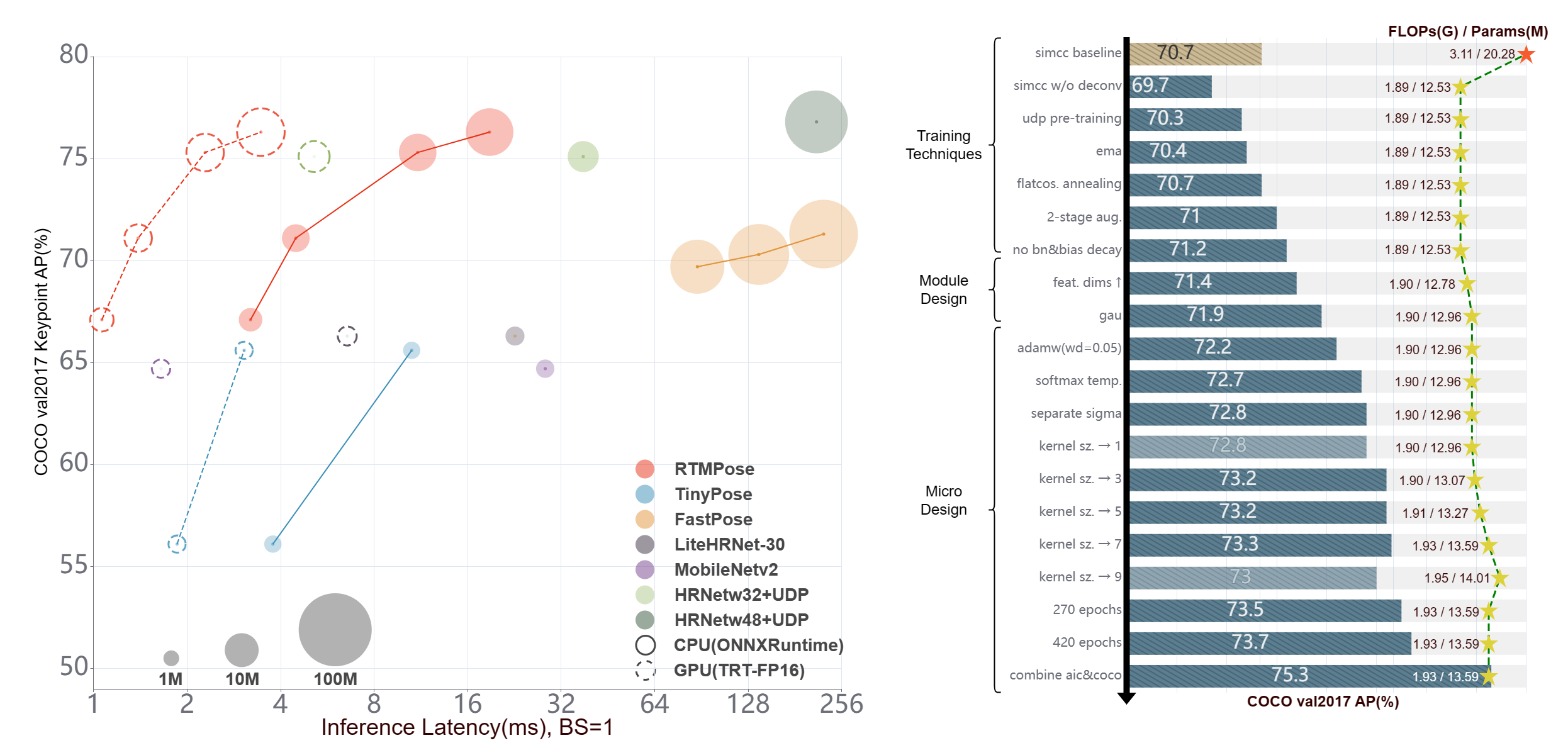
Recent studies on 2D pose estimation have achieved excellent performance on public benchmarks, yet its application in the industrial community still suffers from heavy model parameters and high latency. In order to bridge this gap, we empirically study five aspects that affect the performance of multi-person pose estimation algorithms: paradigm, backbone network, localization algorithm, training strategy, and deployment inference, and present a high-performance real-time multi-person pose estimation framework, RTMPose, based on MMPose. Our RTMPose-m achieves 75.8% AP on COCO with 90+ FPS on an Intel i7-11700 CPU and 430+ FPS on an NVIDIA GTX 1660 Ti GPU, and RTMPose-l achieves 67.0% AP on COCO-WholeBody with 130+ FPS. To further evaluate RTMPose's capability in critical real-time applications, we also report the performance after deploying on the mobile device. Our RTMPose-s achieves 72.2% AP on COCO with 70+ FPS on a Snapdragon 865 chip, outperforming existing open-source libraries. With the help of MMDeploy, our project supports various platforms like CPU, GPU, NVIDIA Jetson, and mobile devices and multiple inference backends such as ONNXRuntime, TensorRT, ncnn, etc.
📄 Table of Contents
- 🥳 🚀 What's New
- 📖 Introduction
- 🙌 Community
- ⚡ Pipeline Performance
- 📊 Model Zoo
- 👀 Visualization
- 😎 Get Started
- 👨🏫 How to Train
- 🏗️ How to Deploy
- 📚 Common Usage
- 📜 Citation
🥳 🚀 What's New 🔝
- Mar. 2023: RTMPose is released. RTMPose-m runs at 430+ FPS and achieves 75.8 mAP on COCO val set.
📖 Introduction 🔝
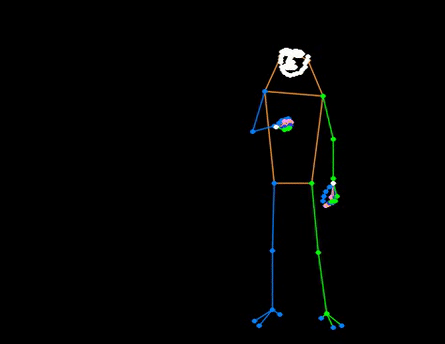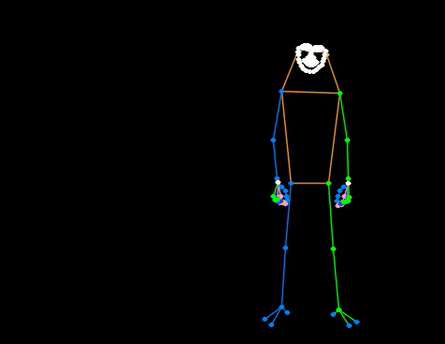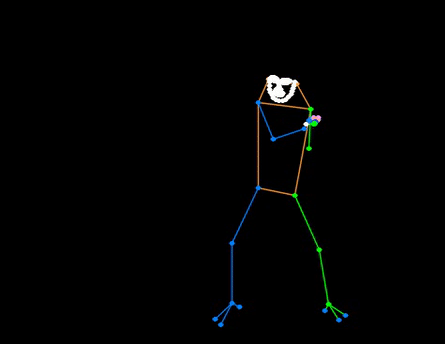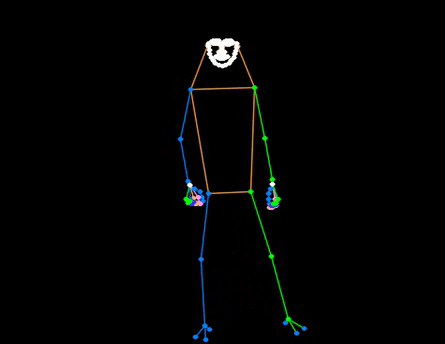
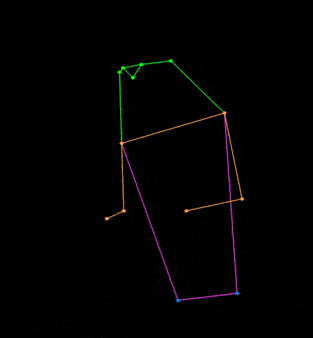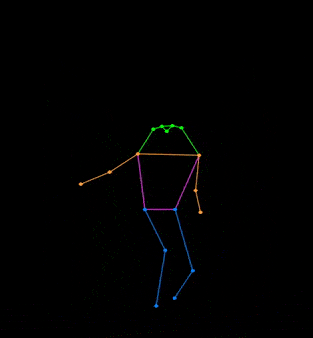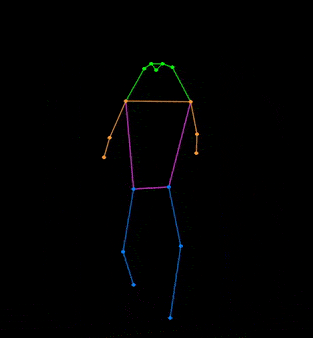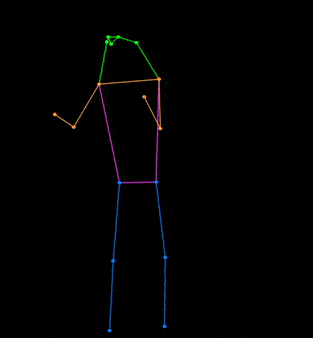


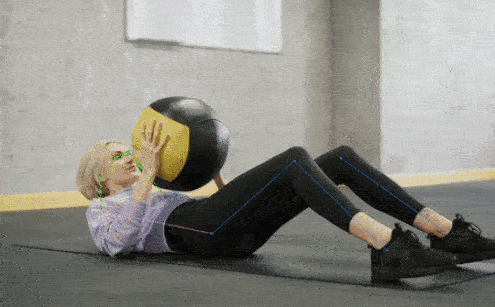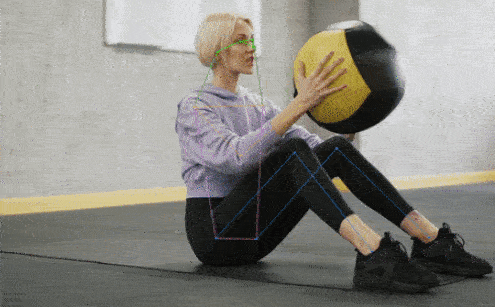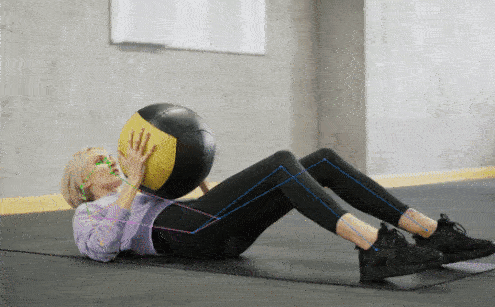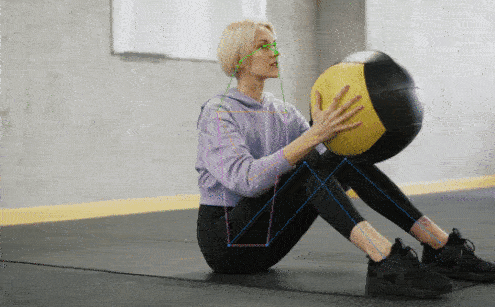


✨ Major Features
- 🚀 High efficiency and high accuracy
| Model | AP(COCO) | CPU-FPS | GPU-FPS | | :---: | :------: | :-----: | :-----: | | t | 68.5 | 300+ | 940+ | | s | 72.2 | 200+ | 710+ | | m | 75.8 | 90+ | 430+ | | l | 76.5 | 50+ | 280+ |
🛠️ Easy to deploy
- Step-by-step deployment tutorials.
- Support various backends including
- ONNX
- TensorRT
- ncnn
- OpenVINO
- etc.
- Support various platforms including
- Linux
- Windows
- NVIDIA Jetson
- ARM
- etc.
🏗️ Design for practical applications
- Pipeline inference API and SDK for
- Python
- C++
- C#
- JAVA
- etc.
🙌 Community 🔝
RTMPose is a long-term project dedicated to the training, optimization and deployment of high-performance real-time pose estimation algorithms in practical scenarios, so we are looking forward to the power from the community. Welcome to share the training configurations and tricks based on RTMPose in different business applications to help more community users!
✨ ✨ ✨
- If you are a new user of RTMPose, we eagerly hope you can fill out this Google Questionnaire/Chinese version, it's very important for our work!
✨ ✨ ✨
Feel free to join our community group for more help:
- WeChat Group:

- Discord Group:
⚡ Pipeline Performance 🔝
Notes
- Pipeline latency is tested under skip-frame settings, the detection interval is 5 frames by defaults.
- Flip test is NOT used.
- Env Setup:
- torch >= 1.7.1
- onnxruntime 1.12.1
- TensorRT 8.4.3.1
- ncnn 20221128
- cuDNN 8.3.2
- CUDA 11.3
| Detection Config | Pose Config | Input Size (Det/Pose) | Model AP (COCO) | Pipeline AP (COCO) | Params (M) (Det/Pose) | Flops (G) (Det/Pose) | ORT-Latency(ms) (i7-11700) | TRT-FP16-Latency(ms) (GTX 1660Ti) | Download | ||
|---|---|---|---|---|---|---|---|---|---|---|---|
| RTMDet-nano | RTMPose-t | 320x320 256x192 |
40.3 67.1 |
64.4 | 0.99 3.34 |
0.31 0.36 |
12.403 | 2.467 | det pose |
||
| RTMDet-nano | RTMPose-s | 320x320 256x192 |
40.3 71.1 |
68.5 | 0.99 5.47 |
0.31 0.68 |
16.658 | 2.730 | det pose |
||
| RTMDet-nano | RTMPose-m | 320x320 256x192 |
40.3 75.3 |
73.2 | 0.99 13.59 |
0.31 1.93 |
26.613 | 4.312 | det pose |
||
| RTMDet-nano | RTMPose-l | 320x320 256x192 |
40.3 76.3 |
74.2 | 0.99 27.66 |
0.31 4.16 |
36.311 | 4.644 | det pose |
||
| RTMDet-m | RTMPose-m | 640x640 256x192 |
62.5 75.3 |
75.7 | 24.66 13.59 |
38.95 1.93 |
- | 6.923 | det pose |
||
| RTMDet-m | RTMPose-l | 640x640 256x192 |
62.5 76.3 |
76.6 | 24.66 27.66 |
38.95 4.16 |
- | 7.204 | det pose |
| Config | Input Size | AP (COCO) | PCK@0.1 (Body8) | AUC (Body8) | EPE (Body8) | Params(M) | FLOPS(G) | ORT-Latency(ms) (i7-11700) | TRT-FP16-Latency(ms) (GTX 1660Ti) | ncnn-FP16-Latency(ms) (Snapdragon 865) | Download |
|---|---|---|---|---|---|---|---|---|---|---|---|
| RTMPose-t | 256x192 | 68.5 | 91.28 | 63.38 | 19.87 | 3.34 | 0.36 | 3.20 | 1.06 | 9.02 | Model |
| RTMPose-s | 256x192 | 72.2 | 92.95 | 66.19 | 17.32 | 5.47 | 0.68 | 4.48 | 1.39 | 13.89 | Model |
| RTMPose-m | 256x192 | 75.8 | 94.13 | 68.53 | 15.42 | 13.59 | 1.93 | 11.06 | 2.29 | 26.44 | Model |
| RTMPose-l | 256x192 | 76.5 | 94.35 | 68.98 | 15.10 | 27.66 | 4.16 | 18.85 | 3.46 | 45.37 | Model |
| RTMPose-m | 384x288 | 77.0 | 94.32 | 69.85 | 14.64 | 13.72 | 4.33 | 24.78 | 3.66 | - | Model |
| RTMPose-l | 384x288 | 77.3 | 94.54 | 70.14 | 14.30 | 27.79 | 9.35 | - | 6.05 | - | Model |
| Config | Input Size | AP (COCO) | PCK@0.1 (Body8) | AUC (Body8) | EPE (Body8) | Params(M) | FLOPS(G) | ORT-Latency(ms) (i7-11700) | TRT-FP16-Latency(ms) (GTX 1660Ti) | ncnn-FP16-Latency(ms) (Snapdragon 865) | Download |
|---|---|---|---|---|---|---|---|---|---|---|---|
| RTMPose-t* | 256x192 | 65.9 | 91.44 | 63.18 | 19.45 | 3.34 | 0.36 | 3.20 | 1.06 | 9.02 | Model |
| RTMPose-s* | 256x192 | 69.7 | 92.45 | 65.15 | 17.85 | 5.47 | 0.68 | 4.48 | 1.39 | 13.89 | Model |
| RTMPose-m* | 256x192 | 74.9 | 94.25 | 68.59 | 15.12 | 13.59 | 1.93 | 11.06 | 2.29 | 26.44 | Model |
| RTMPose-l* | 256x192 | 76.7 | 95.08 | 70.14 | 13.79 | 27.66 | 4.16 | 18.85 | 3.46 | 45.37 | Model |
| RTMPose-m* | 384x288 | 76.6 | 94.64 | 70.38 | 13.98 | 13.72 | 4.33 | 24.78 | 3.66 | - | Model |
| RTMPose-l* | 384x288 | 78.3 | 95.36 | 71.58 | 13.08 | 27.79 | 9.35 | - | 6.05 | - | Model |
| Config | Input Size | AP (COCO) | Params(M) | FLOPS(G) | ORT-Latency(ms) (i7-11700) | TRT-FP16-Latency(ms) (GTX 1660Ti) | ncnn-FP16-Latency(ms) (Snapdragon 865) | Download | |
|---|---|---|---|---|---|---|---|---|---|
| RTMPose-s-aic-coco-pruned | 256x192 | 69.4 | 3.43 | 0.35 | - | - | - | Model |
| Config | Input Size | Whole AP | Whole AR | FLOPS(G) | ORT-Latency(ms) (i7-11700) | TRT-FP16-Latency(ms) (GTX 1660Ti) | Download | ||
|---|---|---|---|---|---|---|---|---|---|
| RTMPose-m | 256x192 | 60.4 | 66.7 | 2.22 | 13.50 | 4.00 | Model | ||
| RTMPose-l | 256x192 | 63.2 | 69.4 | 4.52 | 23.41 | 5.67 | Model | ||
| RTMPose-l | 384x288 | 67.0 | 72.3 | 10.07 | 44.58 | 7.68 | Model |
| Config | Input Size | AP (AP10K) | FLOPS(G) | ORT-Latency(ms) (i7-11700) | TRT-FP16-Latency(ms) (GTX 1660Ti) | Download | |||
|---|---|---|---|---|---|---|---|---|---|
| RTMPose-m | 256x256 | 72.2 | 2.57 | 14.157 | 2.404 | Model |

| Config | Input Size | NME (LaPa) | FLOPS(G) | ORT-Latency(ms) (i7-11700) | TRT-FP16-Latency(ms) (GTX 1660Ti) | Download | |||
|---|---|---|---|---|---|---|---|---|---|
| RTMPose-m (alpha version) | 256x256 | 1.70 | - | - | - | Coming soon |
| Detection Config | Input Size | Model AP (OneHand10K) | Flops (G) | ORT-Latency(ms) (i7-11700) | TRT-FP16-Latency(ms) (GTX 1660Ti) | Download |
|---|---|---|---|---|---|---|
| RTMDet-nano (alpha version) |
320x320 | 76.0 | 0.31 | - | - | Det Model |
Hand5
Hand5and*denote model trained on 5 public datasets:
| Config | Input Size | PCK@0.2 (COCO-Wholebody-Hand) |
PCK@0.2 (Hand5) |
AUC (Hand5) |
EPE (Hand5) |
FLOPS(G) | ORT-Latency(ms) (i7-11700) |
TRT-FP16-Latency(ms) (GTX 1660Ti) |
Download |
|---|---|---|---|---|---|---|---|---|---|
| RTMPose-m* (alpha version) |
256x256 | 81.5 | 96.4 | 83.9 | 5.06 | 2.581 | - | - | Model |
Pretrained Models
We provide the UDP pretraining configs of the CSPNeXt backbone. Find more details in the pretrain_cspnext_udp folder.
AIC+COCO
| Model | Input Size | Params(M) | Flops(G) | AP (GT) |
AR (GT) |
Download |
|---|---|---|---|---|---|---|
| CSPNeXt-tiny | 256x192 | 6.03 | 1.43 | 65.5 | 68.9 | Model |
| CSPNeXt-s | 256x192 | 8.58 | 1.78 | 70.0 | 73.3 | Model |
| CSPNeXt-m | 256x192 | 17.53 | 3.05 | 74.8 | 77.7 | Model |
| CSPNeXt-l | 256x192 | 32.44 | 5.32 | 77.2 | 79.9 | Model |
Body8
*denotes model trained on 7 public datasets:Body8denotes the addition of the OCHuman dataset, in addition to the 7 datasets mentioned above, for evaluation.
| Model | Input Size | Params(M) | Flops(G) | AP (COCO) |
PCK@0.2 (Body8) |
AUC (Body8) |
EPE (Body8) |
Download |
|---|---|---|---|---|---|---|---|---|
| CSPNeXt-tiny* | 256x192 | 6.03 | 1.43 | 65.9 | 96.34 | 63.80 | 18.63 | Model |
| CSPNeXt-s* | 256x192 | 8.58 | 1.78 | 68.7 | 96.59 | 64.92 | 17.84 | Model |
| CSPNeXt-m* | 256x192 | 17.53 | 3.05 | 73.7 | 97.42 | 68.19 | 15.12 | Model |
| CSPNeXt-l* | 256x192 | 32.44 | 5.32 | 75.7 | 97.76 | 69.57 | 13.96 | Model |
| CSPNeXt-m* | 384x288 | 17.53 | 6.86 | 75.8 | 97.60 | 70.18 | 14.04 | Model |
| CSPNeXt-l* | 384x288 | 32.44 | 11.96 | 77.2 | 97.89 | 71.23 | 13.05 | Model |
ImageNet
We also provide the ImageNet classification pre-trained weights of the CSPNeXt backbone. Find more details in RTMDet.
| Model | Input Size | Params(M) | Flops(G) | Top-1 (%) | Top-5 (%) | Download |
|---|---|---|---|---|---|---|
| CSPNeXt-tiny | 224x224 | 2.73 | 0.34 | 69.44 | 89.45 | Model |
| CSPNeXt-s | 224x224 | 4.89 | 0.66 | 74.41 | 92.23 | Model |
| CSPNeXt-m | 224x224 | 13.05 | 1.93 | 79.27 | 94.79 | Model |
| CSPNeXt-l | 224x224 | 27.16 | 4.19 | 81.30 | 95.62 | Model |
👀 Visualization 🔝
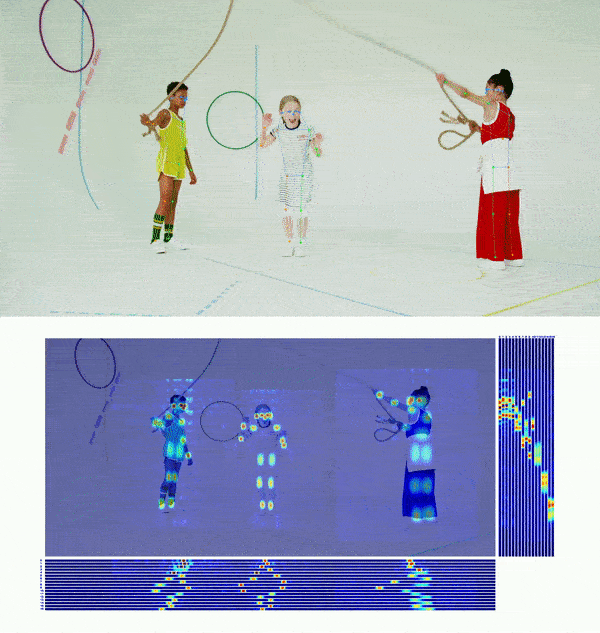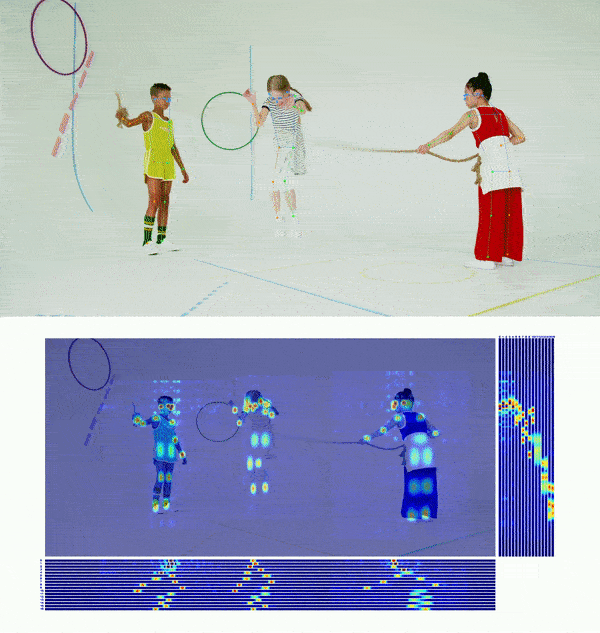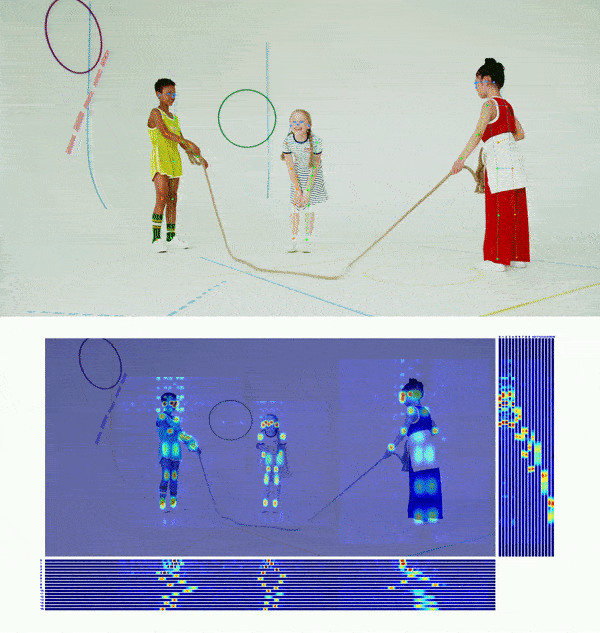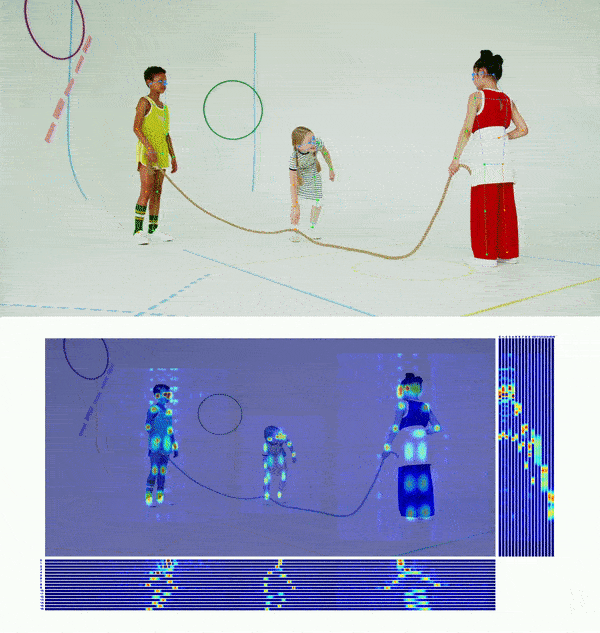
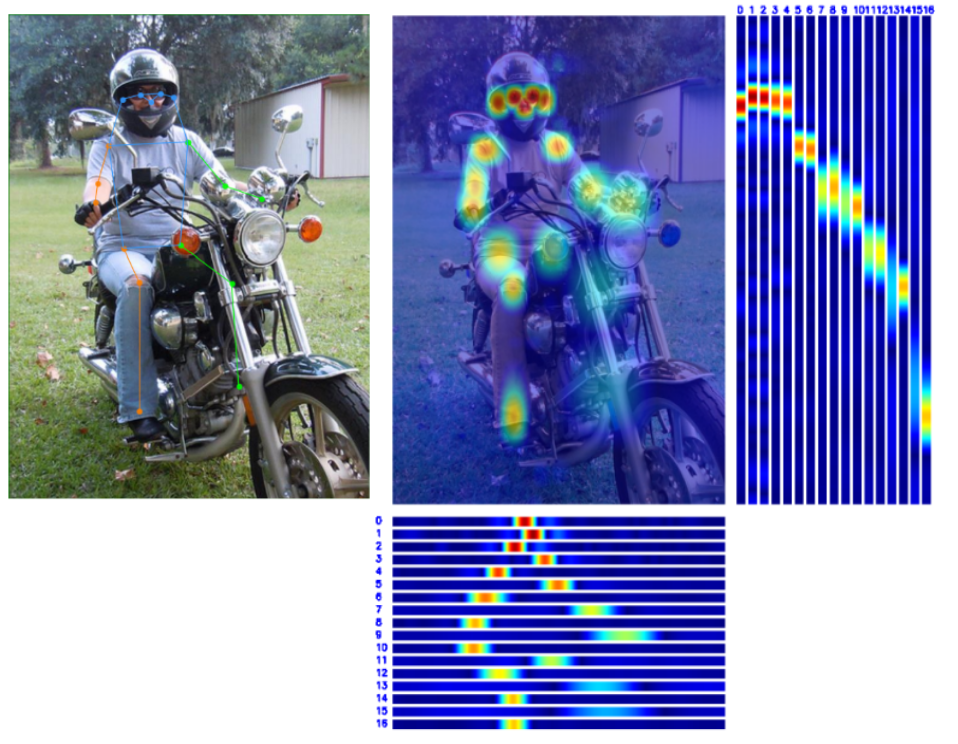
😎 Get Started 🔝
We provide two appoaches to try RTMPose:
- MMPose demo scripts
- Pre-compiled MMDeploy SDK (Recommended)
MMPose demo scripts
MMPose provides demo scripts to conduct inference with existing models.
Note:
- Inferencing with Pytorch can not reach the maximum speed of RTMPose, just for verification.
- Model file can be either a local path or a download link
# go to the mmpose folder
cd ${PATH_TO_MMPOSE}
# inference with rtmdet
python demo/topdown_demo_with_mmdet.py \
projects/rtmpose/rtmdet/person/rtmdet_nano_320-8xb32_coco-person.py \
https://download.openmmlab.com/mmpose/v1/projects/rtmpose/rtmdet_nano_8xb32-100e_coco-obj365-person-05d8511e.pth \
projects/rtmpose/rtmpose/body_2d_keypoint/rtmpose-m_8xb256-420e_coco-256x192.py \
https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/rtmpose-m_simcc-aic-coco_pt-aic-coco_420e-256x192-63eb25f7_20230126.pth \
--input {YOUR_TEST_IMG_or_VIDEO} \
--show
# inference with webcam
python demo/topdown_demo_with_mmdet.py \
projects/rtmpose/rtmdet/person/rtmdet_nano_320-8xb32_coco-person.py \
https://download.openmmlab.com/mmpose/v1/projects/rtmpose/rtmdet_nano_8xb32-100e_coco-obj365-person-05d8511e.pth \
projects/rtmpose/rtmpose/body_2d_keypoint/rtmpose-m_8xb256-420e_coco-256x192.py \
https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/rtmpose-m_simcc-aic-coco_pt-aic-coco_420e-256x192-63eb25f7_20230126.pth \
--input webcam \
--show
Result is as follows:

Pre-compiled MMDeploy SDK (Recommended)
MMDeploy provides a precompiled SDK for Pipeline reasoning on RTMPose projects, where the model used for reasoning is the SDK version.
- All models must by exported by
tools/deploy.pybefore PoseTracker can be used for inference. - For the tutorial of exporting the SDK version model, see SDK Reasoning, and for detailed parameter settings of inference, see Pipeline Reasoning.
Linux
Env Requirements:
- GCC >= 7.5
- cmake >= 3.20
Python Inference
- Install mmdeploy_runtime or mmdeploy_runtime_gpu
# for onnxruntime
pip install mmdeploy-runtime
# for onnxruntime-gpu / tensorrt
pip install mmdeploy-runtime-gpu
- Download Pre-compiled files.
# onnxruntime
# for ubuntu
wget -c https://github.com/open-mmlab/mmdeploy/releases/download/v1.0.0/mmdeploy-1.0.0-linux-x86_64-cxx11abi.tar.gz
# unzip then add third party runtime libraries to the PATH
# for centos7 and lower
wget -c https://github.com/open-mmlab/mmdeploy/releases/download/v1.0.0/mmdeploy-1.0.0-linux-x86_64.tar.gz
# unzip then add third party runtime libraries to the PATH
# onnxruntime-gpu / tensorrt
# for ubuntu
wget -c https://github.com/open-mmlab/mmdeploy/releases/download/v1.0.0/mmdeploy-1.0.0-linux-x86_64-cxx11abi-cuda11.3.tar.gz
# unzip then add third party runtime libraries to the PATH
# for centos7 and lower
wget -c https://github.com/open-mmlab/mmdeploy/releases/download/v1.0.0/mmdeploy-1.0.0-linux-x86_64-cuda11.3.tar.gz
# unzip then add third party runtime libraries to the PATH
- Download the sdk models and unzip to
./example/python. (If you need other models, please export sdk models refer to SDK Reasoning)
# rtmdet-nano + rtmpose-m for cpu sdk
wget https://download.openmmlab.com/mmpose/v1/projects/rtmpose/rtmpose-cpu.zip
unzip rtmpose-cpu.zip
- Inference with
pose_tracker.py:
# go to ./example/python
# Please pass the folder of the model, not the model file
# Format:
# python pose_tracker.py cpu {det work-dir} {pose work-dir} {your_video.mp4}
# Example:
python pose_tracker.py cpu rtmpose-ort/rtmdet-nano/ rtmpose-ort/rtmpose-m/ your_video.mp4
# webcam
python pose_tracker.py cpu rtmpose-ort/rtmdet-nano/ rtmpose-ort/rtmpose-m/ 0
ONNX
# Download pre-compiled files
wget https://github.com/open-mmlab/mmdeploy/releases/download/v1.0.0/mmdeploy-1.0.0-linux-x86_64-cxx11abi.tar.gz
# Unzip files
tar -xzvf mmdeploy-1.0.0-linux-x86_64-cxx11abi.tar.gz
# Go to the sdk folder
cd mmdeploy-1.0.0-linux-x86_64-cxx11abi
# Init environment
source set_env.sh
# If opencv 3+ is not installed on your system, execute the following command.
# If it is installed, skip this command
bash install_opencv.sh
# Compile executable programs
bash build_sdk.sh
# Inference for an image
# Please pass the folder of the model, not the model file
./bin/det_pose rtmpose-ort/rtmdet-nano/ rtmpose-ort/rtmpose-m/ your_img.jpg --device cpu
# Inference for a video
# Please pass the folder of the model, not the model file
./bin/pose_tracker rtmpose-ort/rtmdet-nano/ rtmpose-ort/rtmpose-m/ your_video.mp4 --device cpu
# Inference using webcam
# Please pass the folder of the model, not the model file
./bin/pose_tracker rtmpose-ort/rtmdet-nano/ rtmpose-ort/rtmpose-m/ 0 --device cpu
TensorRT
# Download pre-compiled files
wget https://github.com/open-mmlab/mmdeploy/releases/download/v1.0.0/mmdeploy-1.0.0-linux-x86_64-cxx11abi-cuda11.3.tar.gz
# Unzip files
tar -xzvf mmdeploy-1.0.0-linux-x86_64-cxx11abi-cuda11.3.tar.gz
# Go to the sdk folder
cd mmdeploy-1.0.0-linux-x86_64-cxx11abi-cuda11.3
# Init environment
source set_env.sh
# If opencv 3+ is not installed on your system, execute the following command.
# If it is installed, skip this command
bash install_opencv.sh
# Compile executable programs
bash build_sdk.sh
# Inference for an image
# Please pass the folder of the model, not the model file
./bin/det_pose rtmpose-ort/rtmdet-nano/ rtmpose-ort/rtmpose-m/ your_img.jpg --device cuda
# Inference for a video
# Please pass the folder of the model, not the model file
./bin/pose_tracker rtmpose-ort/rtmdet-nano/ rtmpose-ort/rtmpose-m/ your_video.mp4 --device cuda
# Inference using webcam
# Please pass the folder of the model, not the model file
./bin/pose_tracker rtmpose-ort/rtmdet-nano/ rtmpose-ort/rtmpose-m/ 0 --device cuda
For details, see Pipeline Inference.
Windows
Python Inference
- Install mmdeploy_runtime or mmdeploy_runtime_gpu
# for onnxruntime
pip install mmdeploy-runtime
# download [sdk](https://github.com/open-mmlab/mmdeploy/releases/download/v1.0.0/mmdeploy-1.0.0-windows-amd64.zip) add third party runtime libraries to the PATH
# for onnxruntime-gpu / tensorrt
pip install mmdeploy-runtime-gpu
# download [sdk](https://github.com/open-mmlab/mmdeploy/releases/download/v1.0.0/mmdeploy-1.0.0-windows-amd64-cuda11.3.zip) add third party runtime libraries to the PATH
- Download the sdk models and unzip to
./example/python. (If you need other models, please export sdk models refer to SDK Reasoning)
# rtmdet-nano + rtmpose-m for cpu sdk
wget https://download.openmmlab.com/mmpose/v1/projects/rtmpose/rtmpose-cpu.zip
unzip rtmpose-cpu.zip
- Inference with
pose_tracker.py:
# go to ./example/python
# Please pass the folder of the model, not the model file
python pose_tracker.py cpu rtmpose-ort/rtmdet-nano/ rtmpose-ort/rtmpose-m/ your_video.mp4
# Inference using webcam
# Please pass the folder of the model, not the model file
python pose_tracker.py cpu rtmpose-ort/rtmdet-nano/ rtmpose-ort/rtmpose-m/ 0
Executable Inference
- Install CMake.
- Download the pre-compiled SDK.
- Unzip the SDK and go to the
sdkfolder. - open windows powerShell with administrator privileges
set-ExecutionPolicy RemoteSigned
- Install OpenCV:
# in sdk folder:
.\install_opencv.ps1
- Set environment variables:
# in sdk folder:
. .\set_env.ps1
- Compile the SDK:
# in sdk folder:
# (if you installed opencv by .\install_opencv.ps1)
.\build_sdk.ps1
# (if you installed opencv yourself)
.\build_sdk.ps1 "path/to/folder/of/OpenCVConfig.cmake"
- the executable will be generated in:
example\cpp\build\Release
👨🏫 How to Train 🔝
Please refer to Train and Test.
Tips:
- Please accordinally reduce
batch_sizeandbase_lrwhen your dataset is small. - Guidelines to choose a model
- m: Recommended and Preferred Use
- t/s: For mobile devices with extremely low computing power, or scenarios with stringent inference speed requirements
- l: Suitable for scenarios with strong computing power and not sensitive to speed
🏗️ How to Deploy 🔝
Here is a basic example of deploy RTMPose with MMDeploy.
🧩 Step1. Install MMDeploy
Before starting the deployment, please make sure you install MMPose and MMDeploy correctly.
- Install MMPose, please refer to the MMPose installation guide.
- Install MMDeploy, please refer to the MMDeploy installation guide.
Depending on the deployment backend, some backends require compilation of custom operators, so please refer to the corresponding document to ensure the environment is built correctly according to your needs:
🛠️ Step2. Convert Model
After the installation, you can enjoy the model deployment journey starting from converting PyTorch model to backend model by running MMDeploy's tools/deploy.py.
The detailed model conversion tutorial please refer to the MMDeploy document. Here we only give the example of converting RTMPose.
Here we take converting RTMDet-nano and RTMPose-m to ONNX/TensorRT as an example.
- If you only want to use ONNX, please use:
detection_onnxruntime_static.pyfor RTMDet.pose-detection_simcc_onnxruntime_dynamic.pyfor RTMPose.
- If you want to use TensorRT, please use:
detection_tensorrt_static-320x320.pyfor RTMDet.pose-detection_simcc_tensorrt_dynamic-256x192.pyfor RTMPose.
If you want to customize the settings in the deployment config for your requirements, please refer to MMDeploy config tutorial.
In this tutorial, we organize files as follows:
|----mmdeploy
|----mmdetection
|----mmpose
ONNX
# go to the mmdeploy folder
cd ${PATH_TO_MMDEPLOY}
# run the command to convert RTMDet
# Model file can be either a local path or a download link
python tools/deploy.py \
configs/mmdet/detection/detection_onnxruntime_static.py \
../mmpose/projects/rtmpose/rtmdet/person/rtmdet_nano_320-8xb32_coco-person.py \
https://download.openmmlab.com/mmpose/v1/projects/rtmpose/rtmdet_nano_8xb32-100e_coco-obj365-person-05d8511e.pth \
demo/resources/human-pose.jpg \
--work-dir rtmpose-ort/rtmdet-nano \
--device cpu \
--show \
--dump-info # dump sdk info
# run the command to convert RTMPose
# Model file can be either a local path or a download link
python tools/deploy.py \
configs/mmpose/pose-detection_simcc_onnxruntime_dynamic.py \
../mmpose/projects/rtmpose/rtmpose/body_2d_keypoint/rtmpose-m_8xb256-420e_coco-256x192.py \
https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/rtmpose-m_simcc-aic-coco_pt-aic-coco_420e-256x192-63eb25f7_20230126.pth \
demo/resources/human-pose.jpg \
--work-dir rtmpose-ort/rtmpose-m \
--device cpu \
--show \
--dump-info # dump sdk info
The converted model file is {work-dir}/end2end.onnx by defaults.
TensorRT
# go to the mmdeploy folder
cd ${PATH_TO_MMDEPLOY}
# run the command to convert RTMDet
# Model file can be either a local path or a download link
python tools/deploy.py \
configs/mmdet/detection/detection_tensorrt_static-320x320.py \
../mmpose/projects/rtmpose/rtmdet/person/rtmdet_nano_320-8xb32_coco-person.py \
https://download.openmmlab.com/mmpose/v1/projects/rtmpose/rtmdet_nano_8xb32-100e_coco-obj365-person-05d8511e.pth \
demo/resources/human-pose.jpg \
--work-dir rtmpose-trt/rtmdet-nano \
--device cuda:0 \
--show \
--dump-info # dump sdk info
# run the command to convert RTMPose
# Model file can be either a local path or a download link
python tools/deploy.py \
configs/mmpose/pose-detection_simcc_tensorrt_dynamic-256x192.py \
../mmpose/projects/rtmpose/rtmpose/body_2d_keypoint/rtmpose-m_8xb256-420e_coco-256x192.py \
https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/rtmpose-m_simcc-aic-coco_pt-aic-coco_420e-256x192-63eb25f7_20230126.pth \
demo/resources/human-pose.jpg \
--work-dir rtmpose-trt/rtmpose-m \
--device cuda:0 \
--show \
--dump-info # dump sdk info
The converted model file is {work-dir}/end2end.engine by defaults.
🎊 If the script runs successfully, you will see the following files:

Advanced Setting
To convert the model with TRT-FP16, you can enable the fp16 mode in your deploy config:
# in MMDeploy config
backend_config = dict(
type='tensorrt',
common_config=dict(
fp16_mode=True # enable fp16
))
🕹️ Step3. Inference with SDK
We provide both Python and C++ inference API with MMDeploy SDK.
To use SDK, you need to dump the required info during converting the model. Just add --dump-info to the model conversion command.
# RTMDet
# Model file can be either a local path or a download link
python tools/deploy.py \
configs/mmdet/detection/detection_onnxruntime_dynamic.py \
../mmpose/projects/rtmpose/rtmdet/person/rtmdet_nano_320-8xb32_coco-person.py \
https://download.openmmlab.com/mmpose/v1/projects/rtmpose/rtmdet_nano_8xb32-100e_coco-obj365-person-05d8511e.pth \
demo/resources/human-pose.jpg \
--work-dir rtmpose-ort/rtmdet-nano \
--device cpu \
--show \
--dump-info # dump sdk info
# RTMPose
# Model file can be either a local path or a download link
python tools/deploy.py \
configs/mmpose/pose-detection_simcc_onnxruntime_dynamic.py \
../mmpose/projects/rtmpose/rtmpose/body_2d_keypoint/rtmpose-m_8xb256-420e_coco-256x192.py \
https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/rtmpose-m_simcc-aic-coco_pt-aic-coco_420e-256x192-63eb25f7_20230126.pth \
demo/resources/human-pose.jpg \
--work-dir rtmpose-ort/rtmpose-m \
--device cpu \
--show \
--dump-info # dump sdk info
After running the command, it will dump 3 json files additionally for the SDK:
|----{work-dir}
|----end2end.onnx # ONNX model
|----end2end.engine # TensorRT engine file
|----pipeline.json #
|----deploy.json # json files for the SDK
|----detail.json #
Python API
Here is a basic example of SDK Python API:
# Copyright (c) OpenMMLab. All rights reserved.
import argparse
import cv2
import numpy as np
from mmdeploy_runtime import PoseDetector
def parse_args():
parser = argparse.ArgumentParser(
description='show how to use sdk python api')
parser.add_argument('device_name', help='name of device, cuda or cpu')
parser.add_argument(
'model_path',
help='path of mmdeploy SDK model dumped by model converter')
parser.add_argument('image_path', help='path of an image')
parser.add_argument(
'--bbox',
default=None,
nargs='+',
type=int,
help='bounding box of an object in format (x, y, w, h)')
args = parser.parse_args()
return args
def main():
args = parse_args()
img = cv2.imread(args.image_path)
detector = PoseDetector(
model_path=args.model_path, device_name=args.device_name, device_id=0)
if args.bbox is None:
result = detector(img)
else:
# converter (x, y, w, h) -> (left, top, right, bottom)
print(args.bbox)
bbox = np.array(args.bbox, dtype=int)
bbox[2:] += bbox[:2]
result = detector(img, bbox)
print(result)
_, point_num, _ = result.shape
points = result[:, :, :2].reshape(point_num, 2)
for [x, y] in points.astype(int):
cv2.circle(img, (x, y), 1, (0, 255, 0), 2)
cv2.imwrite('output_pose.png', img)
if __name__ == '__main__':
main()
C++ API
Here is a basic example of SDK C++ API:
#include "mmdeploy/detector.hpp"
#include "opencv2/imgcodecs/imgcodecs.hpp"
#include "utils/argparse.h"
#include "utils/visualize.h"
DEFINE_ARG_string(model, "Model path");
DEFINE_ARG_string(image, "Input image path");
DEFINE_string(device, "cpu", R"(Device name, e.g. "cpu", "cuda")");
DEFINE_string(output, "detector_output.jpg", "Output image path");
DEFINE_double(det_thr, .5, "Detection score threshold");
int main(int argc, char* argv[]) {
if (!utils::ParseArguments(argc, argv)) {
return -1;
}
cv::Mat img = cv::imread(ARGS_image);
if (img.empty()) {
fprintf(stderr, "failed to load image: %s\n", ARGS_image.c_str());
return -1;
}
// construct a detector instance
mmdeploy::Detector detector(mmdeploy::Model{ARGS_model}, mmdeploy::Device{FLAGS_device});
// apply the detector, the result is an array-like class holding references to
// `mmdeploy_detection_t`, will be released automatically on destruction
mmdeploy::Detector::Result dets = detector.Apply(img);
// visualize
utils::Visualize v;
auto sess = v.get_session(img);
int count = 0;
for (const mmdeploy_detection_t& det : dets) {
if (det.score > FLAGS_det_thr) { // filter bboxes
sess.add_det(det.bbox, det.label_id, det.score, det.mask, count++);
}
}
if (!FLAGS_output.empty()) {
cv::imwrite(FLAGS_output, sess.get());
}
return 0;
}
To build C++ example, please add MMDeploy package in your CMake project as following:
find_package(MMDeploy REQUIRED)
target_link_libraries(${name} PRIVATE mmdeploy ${OpenCV_LIBS})
Other languages
🚀 Step4. Pipeline Inference
Inference for images
If the user has MMDeploy compiled correctly, you will see the det_pose executable under the mmdeploy/build/bin/.
# go to the mmdeploy folder
cd ${PATH_TO_MMDEPLOY}/build/bin/
# inference for an image
./det_pose rtmpose-ort/rtmdet-nano/ rtmpose-ort/rtmpose-m/ your_img.jpg --device cpu
required arguments:
det_model Object detection model path [string]
pose_model Pose estimation model path [string]
image Input image path [string]
optional arguments:
--device Device name, e.g. "cpu", "cuda" [string = "cpu"]
--output Output image path [string = "det_pose_output.jpg"]
--skeleton Path to skeleton data or name of predefined skeletons:
"coco" [string = "coco", "coco-wholoebody"]
--det_label Detection label use for pose estimation [int32 = 0]
(0 refers to 'person' in coco)
--det_thr Detection score threshold [double = 0.5]
--det_min_bbox_size Detection minimum bbox size [double = -1]
--pose_thr Pose key-point threshold [double = 0]
API Example
Inference for a video
If the user has MMDeploy compiled correctly, you will see the pose_tracker executable under the mmdeploy/build/bin/.
- pass
0toinputcan inference from a webcam
# go to the mmdeploy folder
cd ${PATH_TO_MMDEPLOY}/build/bin/
# inference for a video
./pose_tracker rtmpose-ort/rtmdet-nano/ rtmpose-ort/rtmpose-m/ your_video.mp4 --device cpu
required arguments:
det_model Object detection model path [string]
pose_model Pose estimation model path [string]
input Input video path or camera index [string]
optional arguments:
--device Device name, e.g. "cpu", "cuda" [string = "cpu"]
--output Output video path or format string [string = ""]
--output_size Long-edge of output frames [int32 = 0]
--flip Set to 1 for flipping the input horizontally [int32 = 0]
--show Delay passed to `cv::waitKey` when using `cv::imshow`;
-1: disable [int32 = 1]
--skeleton Path to skeleton data or name of predefined skeletons:
"coco", "coco-wholebody" [string = "coco"]
--background Output background, "default": original image, "black":
black background [string = "default"]
--det_interval Detection interval [int32 = 1]
--det_label Detection label use for pose estimation [int32 = 0]
(0 refers to 'person' in coco)
--det_thr Detection score threshold [double = 0.5]
--det_min_bbox_size Detection minimum bbox size [double = -1]
--det_nms_thr NMS IOU threshold for merging detected bboxes and
bboxes from tracked targets [double = 0.7]
--pose_max_num_bboxes Max number of bboxes used for pose estimation per frame
[int32 = -1]
--pose_kpt_thr Threshold for visible key-points [double = 0.5]
--pose_min_keypoints Min number of key-points for valid poses, -1 indicates
ceil(n_kpts/2) [int32 = -1]
--pose_bbox_scale Scale for expanding key-points to bbox [double = 1.25]
--pose_min_bbox_size Min pose bbox size, tracks with bbox size smaller than
the threshold will be dropped [double = -1]
--pose_nms_thr NMS OKS/IOU threshold for suppressing overlapped poses,
useful when multiple pose estimations collapse to the
same target [double = 0.5]
--track_iou_thr IOU threshold for associating missing tracks
[double = 0.4]
--track_max_missing Max number of missing frames before a missing tracks is
removed [int32 = 10]
API Example
📚 Common Usage 🔝
🚀 Inference Speed Test 🔝
If you need to test the inference speed of the model under the deployment framework, MMDeploy provides a convenient tools/profiler.py script.
The user needs to prepare a folder for the test images ./test_images, the profiler will randomly read images from this directory for the model speed test.
python tools/profiler.py \
configs/mmpose/pose-detection_simcc_onnxruntime_dynamic.py \
{RTMPOSE_PROJECT}/rtmpose/body_2d_keypoint/rtmpose-m_8xb256-420e_coco-256x192.py \
../test_images \
--model {WORK_DIR}/end2end.onnx \
--shape 256x192 \
--device cpu \
--warmup 50 \
--num-iter 200
The result is as follows:
01/30 15:06:35 - mmengine - INFO - [onnxruntime]-70 times per count: 8.73 ms, 114.50 FPS
01/30 15:06:36 - mmengine - INFO - [onnxruntime]-90 times per count: 9.05 ms, 110.48 FPS
01/30 15:06:37 - mmengine - INFO - [onnxruntime]-110 times per count: 9.87 ms, 101.32 FPS
01/30 15:06:37 - mmengine - INFO - [onnxruntime]-130 times per count: 9.99 ms, 100.10 FPS
01/30 15:06:38 - mmengine - INFO - [onnxruntime]-150 times per count: 10.39 ms, 96.29 FPS
01/30 15:06:39 - mmengine - INFO - [onnxruntime]-170 times per count: 10.77 ms, 92.86 FPS
01/30 15:06:40 - mmengine - INFO - [onnxruntime]-190 times per count: 10.98 ms, 91.05 FPS
01/30 15:06:40 - mmengine - INFO - [onnxruntime]-210 times per count: 11.19 ms, 89.33 FPS
01/30 15:06:41 - mmengine - INFO - [onnxruntime]-230 times per count: 11.16 ms, 89.58 FPS
01/30 15:06:42 - mmengine - INFO - [onnxruntime]-250 times per count: 11.06 ms, 90.41 FPS
----- Settings:
+------------+---------+
| batch size | 1 |
| shape | 256x192 |
| iterations | 200 |
| warmup | 50 |
+------------+---------+
----- Results:
+--------+------------+---------+
| Stats | Latency/ms | FPS |
+--------+------------+---------+
| Mean | 11.060 | 90.412 |
| Median | 11.852 | 84.375 |
| Min | 7.812 | 128.007 |
| Max | 13.690 | 73.044 |
+--------+------------+---------+
If you want to learn more details of profiler, you can refer to the Profiler Docs.
📊 Model Test 🔝
If you need to test the inference accuracy of the model on the deployment backend, MMDeploy provides a convenient tools/test.py script.
python tools/test.py \
configs/mmpose/pose-detection_simcc_onnxruntime_dynamic.py \
{RTMPOSE_PROJECT}/rtmpose/body_2d_keypoint/rtmpose-m_8xb256-420e_coco-256x192.py \
--model {PATH_TO_MODEL}/rtmpose_m.pth \
--device cpu
You can also refer to MMDeploy Docs for more details.
📜 Citation 🔝
If you find RTMPose useful in your research, please consider cite:
@misc{https://doi.org/10.48550/arxiv.2303.07399,
doi = {10.48550/ARXIV.2303.07399},
url = {https://arxiv.org/abs/2303.07399},
author = {Jiang, Tao and Lu, Peng and Zhang, Li and Ma, Ningsheng and Han, Rui and Lyu, Chengqi and Li, Yining and Chen, Kai},
keywords = {Computer Vision and Pattern Recognition (cs.CV), FOS: Computer and information sciences, FOS: Computer and information sciences},
title = {RTMPose: Real-Time Multi-Person Pose Estimation based on MMPose},
publisher = {arXiv},
year = {2023},
copyright = {Creative Commons Attribution 4.0 International}
}
@misc{mmpose2020,
title={OpenMMLab Pose Estimation Toolbox and Benchmark},
author={MMPose Contributors},
howpublished = {\url{https://github.com/open-mmlab/mmpose}},
year={2020}
}