DDOD
Disentangle Your Dense Object Detector
Abstract
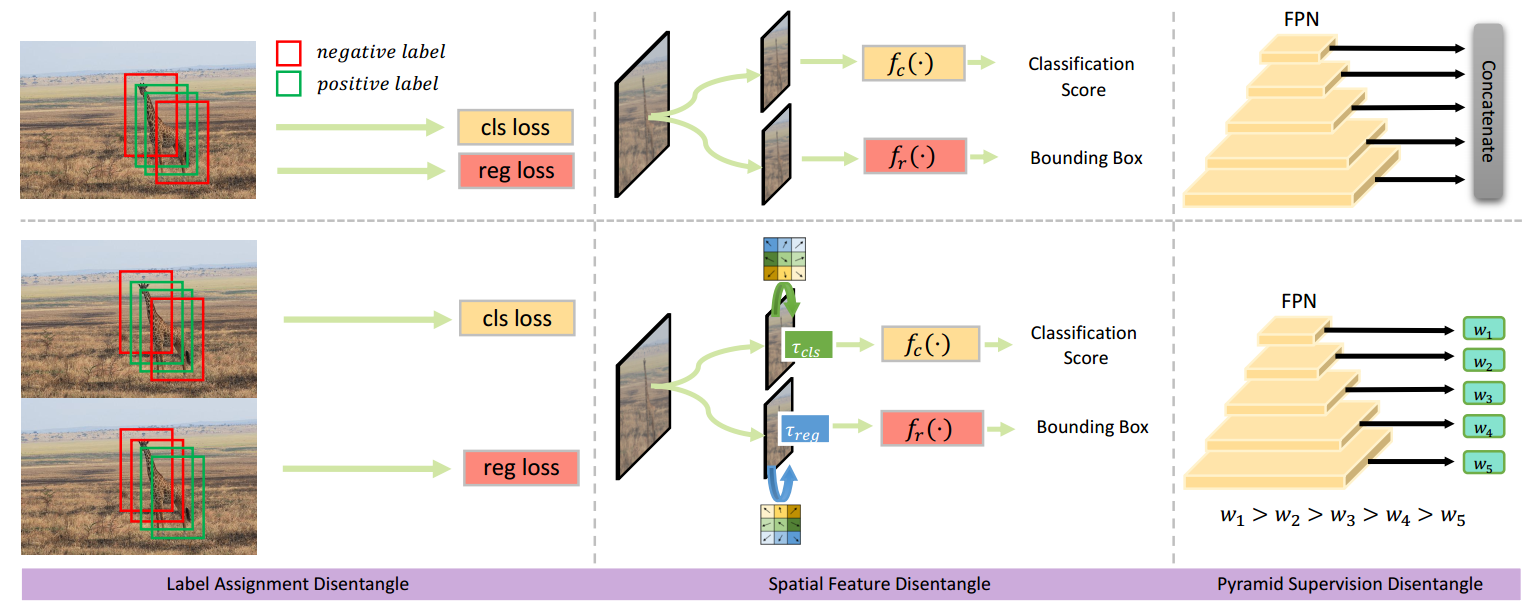
Deep learning-based dense object detectors have achieved great success in the past few years and have been applied to numerous multimedia applications such as video understanding. However, the current training pipeline for dense detectors is compromised to lots of conjunctions that may not hold. In this paper, we investigate three such important conjunctions: 1) only samples assigned as positive in classification head are used to train the regression head; 2) classification and regression share the same input feature and computational fields defined by the parallel head architecture; and 3) samples distributed in different feature pyramid layers are treated equally when computing the loss. We first carry out a series of pilot experiments to show disentangling such conjunctions can lead to persistent performance improvement. Then, based on these findings, we propose Disentangled Dense Object Detector(DDOD), in which simple and effective disentanglement mechanisms are designed and integrated into the current state-of-the-art dense object detectors. Extensive experiments on MS COCO benchmark show that our approach can lead to 2.0 mAP, 2.4 mAP and 2.2 mAP absolute improvements on RetinaNet, FCOS, and ATSS baselines with negligible extra overhead. Notably, our best model reaches 55.0 mAP on the COCO test-dev set and 93.5 AP on the hard subset of WIDER FACE, achieving new state-of-the-art performance on these two competitive benchmarks. Code is available at https://github.com/zehuichen123/DDOD.
Results and Models
| Model |
Backbone |
Style |
Lr schd |
Mem (GB) |
box AP |
Config |
Download |
| DDOD-ATSS |
R-50 |
pytorch |
1x |
3.4 |
41.7 |
config |
model | log |
Citation
@inproceedings{chen2021disentangle,
title={Disentangle Your Dense Object Detector},
author={Chen, Zehui and Yang, Chenhongyi and Li, Qiaofei and Zhao, Feng and Zha, Zheng-Jun and Wu, Feng},
booktitle={Proceedings of the 29th ACM International Conference on Multimedia},
pages={4939--4948},
year={2021}
}

 DJW
c16313bb6a
第一次提交
DJW
c16313bb6a
第一次提交