
README.md 6.3 KB
LD
Abstract
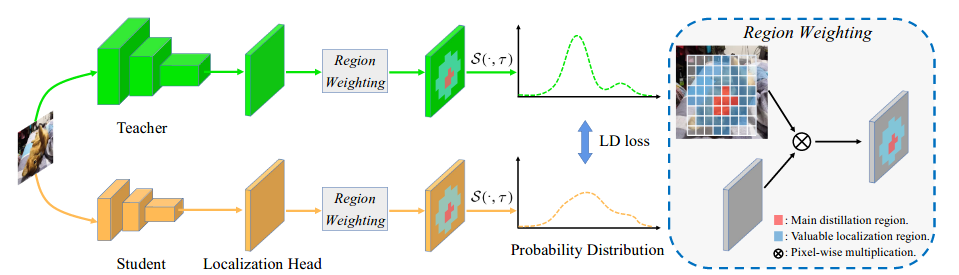
Knowledge distillation (KD) has witnessed its powerful capability in learning compact models in object detection. Previous KD methods for object detection mostly focus on imitating deep features within the imitation regions instead of mimicking classification logits due to its inefficiency in distilling localization information. In this paper, by reformulating the knowledge distillation process on localization, we present a novel localization distillation (LD) method which can efficiently transfer the localization knowledge from the teacher to the student. Moreover, we also heuristically introduce the concept of valuable localization region that can aid to selectively distill the semantic and localization knowledge for a certain region. Combining these two new components, for the first time, we show that logit mimicking can outperform feature imitation and localization knowledge distillation is more important and efficient than semantic knowledge for distilling object detectors. Our distillation scheme is simple as well as effective and can be easily applied to different dense object detectors. Experiments show that our LD can boost the AP score of GFocal-ResNet-50 with a single-scale 1× training schedule from 40.1 to 42.1 on the COCO benchmark without any sacrifice on the inference speed.
Results and Models
GFocalV1 with LD
| Teacher | Student | Training schedule | Mini-batch size | AP (val) | Config | Download |
|---|---|---|---|---|---|---|
| -- | R-18 | 1x | 6 | 35.8 | ||
| R-101 | R-18 | 1x | 6 | 36.5 | config | model | log |
| -- | R-34 | 1x | 6 | 38.9 | ||
| R-101 | R-34 | 1x | 6 | 39.9 | config | model | log |
| -- | R-50 | 1x | 6 | 40.1 | ||
| R-101 | R-50 | 1x | 6 | 41.0 | config | model | log |
| -- | R-101 | 2x | 6 | 44.6 | ||
| R-101-DCN | R-101 | 2x | 6 | 45.5 | config | model | log |
Note
- Meaning of Config name: ld_r18(student model)_gflv1(based on gflv1)_r101(teacher model)_fpn(neck)_coco(dataset)_1x(12 epoch).py
Citation
@Inproceedings{zheng2022LD,
title={Localization Distillation for Dense Object Detection},
author= {Zheng, Zhaohui and Ye, Rongguang and Wang, Ping and Ren, Dongwei and Zuo, Wangmeng and Hou, Qibin and Cheng, Mingming},
booktitle={CVPR},
year={2022}
}