
 DJW
c16313bb6a
第一次提交
DJW
c16313bb6a
第一次提交
|
1 năm trước cách đây | |
|---|---|---|
| .. | ||
| README.md | 1 năm trước cách đây | |
| atss_r50-caffe_fpn_dyhead_1x_coco.py | 1 năm trước cách đây | |
| atss_r50_fpn_dyhead_1x_coco.py | 1 năm trước cách đây | |
| atss_swin-l-p4-w12_fpn_dyhead_ms-2x_coco.py | 1 năm trước cách đây | |
| metafile.yml | 1 năm trước cách đây | |
README.md
DyHead
Dynamic Head: Unifying Object Detection Heads with Attentions
Abstract
The complex nature of combining localization and classification in object detection has resulted in the flourished development of methods. Previous works tried to improve the performance in various object detection heads but failed to present a unified view. In this paper, we present a novel dynamic head framework to unify object detection heads with attentions. By coherently combining multiple self-attention mechanisms between feature levels for scale-awareness, among spatial locations for spatial-awareness, and within output channels for task-awareness, the proposed approach significantly improves the representation ability of object detection heads without any computational overhead. Further experiments demonstrate that the effectiveness and efficiency of the proposed dynamic head on the COCO benchmark. With a standard ResNeXt-101-DCN backbone, we largely improve the performance over popular object detectors and achieve a new state-of-the-art at 54.0 AP. Furthermore, with latest transformer backbone and extra data, we can push current best COCO result to a new record at 60.6 AP.
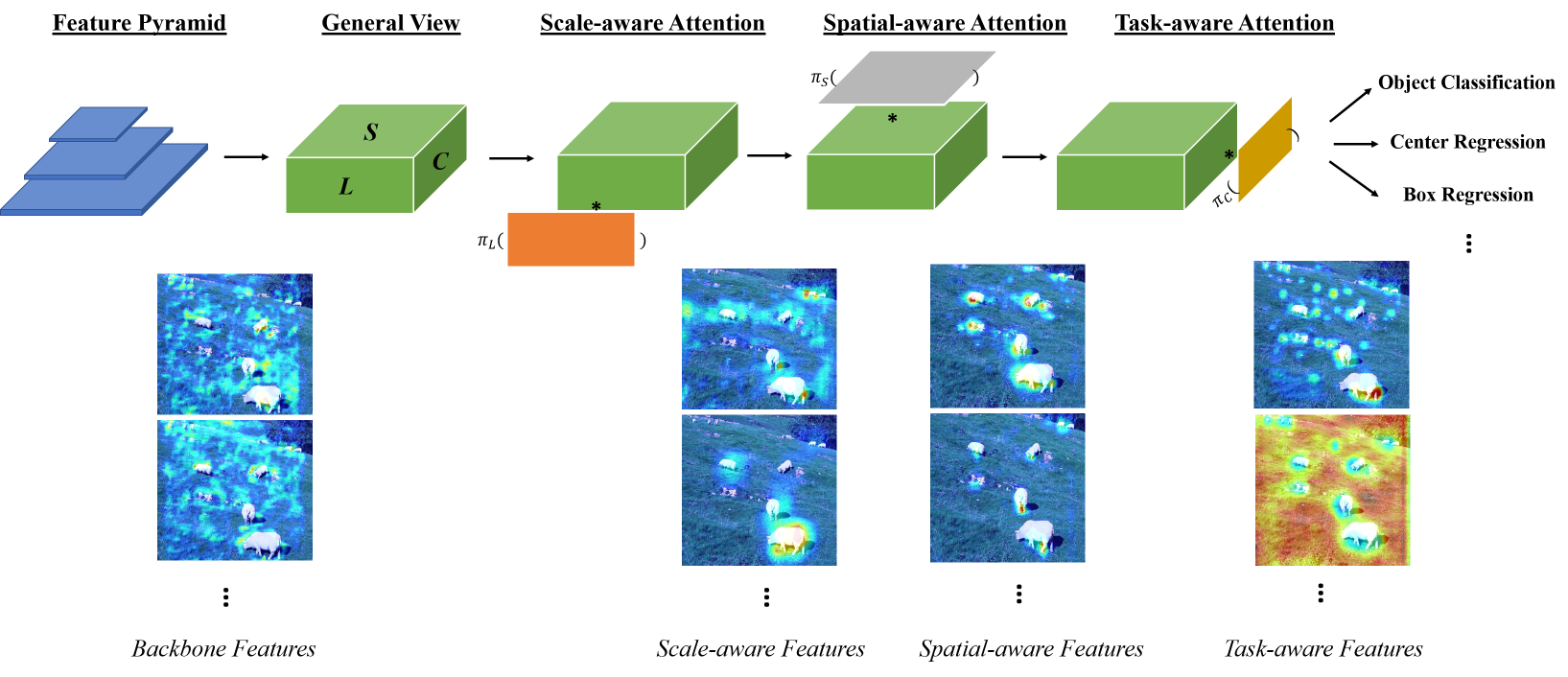
Results and Models
| Method | Backbone | Style | Setting | Lr schd | Mem (GB) | Inf time (fps) | box AP | Config | Download |
|---|---|---|---|---|---|---|---|---|---|
| ATSS | R-50 | caffe | reproduction | 1x | 5.4 | 13.2 | 42.5 | config | model | log |
| ATSS | R-50 | pytorch | simple | 1x | 4.9 | 13.7 | 43.3 | config | model | log |
- We trained the above models with 4 GPUs and 4
samples_per_gpu. - The
reproductionsetting aims to reproduce the official implementation based on Detectron2. - The
simplesetting serves as a minimum example to use DyHead in MMDetection. Specifically,- it adds
DyHeadtoneckafterFPN - it sets
stacked_convs=0tobbox_head
- it adds
- The
simplesetting achieves higher AP than the original implementation. We have not conduct ablation study between the two settings.dict(type='Pad', size_divisor=128)may further improve AP by prefer spatial alignment across pyramid levels, although large padding reduces efficiency.
We also trained the model with Swin-L backbone. Results are as below.
| Method | Backbone | Style | Setting | Lr schd | mstrain | box AP | Config | Download |
|---|---|---|---|---|---|---|---|---|
| ATSS | Swin-L | caffe | reproduction | 2x | 480~1200 | 56.2 | config | model | log |
Relation to Other Methods
- DyHead can be regarded as an improved SEPC with DyReLU modules and simplified SE blocks.
- Xiyang Dai et al., the author team of DyHead, adopt it for Dynamic DETR. The description of Dynamic Encoder in Sec. 3.2 will help you understand DyHead.
Citation
@inproceedings{DyHead_CVPR2021,
author = {Dai, Xiyang and Chen, Yinpeng and Xiao, Bin and Chen, Dongdong and Liu, Mengchen and Yuan, Lu and Zhang, Lei},
title = {Dynamic Head: Unifying Object Detection Heads With Attentions},
booktitle = {Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)},
year = {2021}
}